Revealing New Insights Through Machine Learning: An Application in Prepayment Modeling

Emergence of Artificial Intelligence and Machine Learning
The rise of ChatGPT has brought generative artificial intelligence (GenAI) into the mainstream, accelerating adoption across industries ranging from healthcare to banking. The pace at which (Gen)AI is being used is outpacing prior technological advances, putting pressure on individuals and companies to adapt their ways of working to this new technology. While GenAI uses data to create new content, traditional AI is typically designed to perform specific tasks such as making predictions or classifications. Both approaches are built on complex machine learning (ML) models which, when applied correctly, can be highly effective even on a stand-alone basis.
Figure 1: Model development steps
Though ML techniques are known for their accuracy, a major challenge lies in their complexity and limited interpretability. Unlocking the full potential of ML requires not only technical expertise, but also deep domain knowledge. Asset and Liability Management (ALM) departments can benefit from ML, for example in the area of behavioral modeling. In this article, we explore the application of ML in prepayment modeling (data processing, segmentation, estimation) based on research conducted at a Dutch bank. The findings demonstrate how ML can improve the accuracy of prepayment models, leading to better cashflow forecasts and, consequently, a more accurate hedge. By building ML capabilities in this context, ALM teams can play a key role in shaping the future of behavioral modeling throughout the whole model development process.
Prepayment Modeling and Machine Learning
Prepayment risk is a critical concern for financial institutions, particularly in the mortgage sector, where borrowers have the option to repay (a part of) their loans earlier than contractually agreed. While prepayments can be beneficial for borrowers (allowing them to refinance at lower interest rates or reduce their debt obligations) they present several challenges for financial institutions. Uncertainty in prepayment behaviour makes it harder to predict the duration mismatch and the corresponding interest rate hedge.
Effective prepayment modeling by accurately forecasting borrower behavior is crucial for financial institutions seeking to manage interest rate risks. Improved forecasting enables institutions to better anticipate cash flow fluctuations and implement more robust hedging strategies. To facilitate the modeling, data is segmented based on similar prepayment characteristics. This segmentation is often based on expert judgment and extensive data analysis, accounting for factors like loan age, interest rate, type, and borrower characteristics. Each segment is then analyzed through tailored prepayment models, such as a logistic regression or survival models.1
ML techniques offer significant potential to enhance segmentation and estimation in prepayment modeling. In rapidly changing interest rate environments, traditional models often struggle to accurately capture borrower behavior that deviates from conventional financial logic. In contrast, ML models can detect complex, non-linear patterns and adapt to changing behaviour, improving predictive accuracy by uncovering hidden relationships. Investigating such relationships becomes particularly relevant when borrower actions undermine traditional assumptions, as was the case in early 2021, when interest rates began to rise but prepayment rates did not decline immediately.
Real-world application
In collaboration with a Dutch bank, we conducted research on the application of ML in prepayment modeling within the Dutch mortgage market. The applications include data processing, segmentation, and estimation followed by an interpretation of the results with the use of ML specific interpretability metrics. Despite being constrained by limited computational power, the ML-based approaches outperformed the traditional methods, demonstrating superior predictive accuracy and stronger ability to capture complex patterns in the data. The specific applications are highlighted below.
Data processing
One of the first steps in model development is ensuring that the data is fit for use. An ML technique that can be commonly applied for outlier detection is the DBSCAN algorithm. This clustering method relies on the concept of distance to identify groups of observations, flagging those that do not fit well into any cluster as potential outliers. Since DBSCAN requires the user to define specific parameters, it offers flexibility and robustness in detecting outliers across a wide range of datasets.
Another example is an isolation forest algorithm. It detects outliers by randomly splitting the data and measuring how quickly a point becomes isolated. Outliers tend to be separated faster, since they share fewer similarities with the rest of the data. The model assigns an anomaly score based on how few splits were needed to isolate each point, where fewer splits suggest a higher likelihood of being an outlier. The isolation forest method is computationally efficient, performs well with large datasets, and does not require labelled data.
Segmentation
Following the data processing step, where outliers are identified, evaluated, and treated appropriately, the next phase in model development involves analyzing the dataset to define economically meaningful segments. ML-based clustering techniques are well-suited for deriving segments from data. It is important to note that mortgage data is generally high-dimensional and contains a large number of observations. As a result, clustering techniques must be carefully selected to ensure they can handle high-volume data efficiently within reasonable timelines. Two effective techniques for this purpose are K-means clustering and decision trees.
K-means clustering is an ML algorithm used to partition data into distinct segments based on similarity. Data points that are close to each other in a multi-dimensional space are grouped together, as illustrated in Figure 2. In the context of mortgage portfolio segmentation, K-means enables the grouping of loans with similar characteristics, making the segmentation process data-driven rather than based on predefined rules.
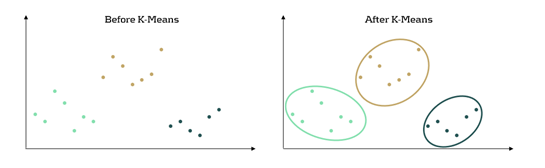
Figure 2: K-Means concept in a 2-dimensional space. Before, the dataset is seen as a whole unstructured dataset while K-means reveals three different segments in the data
Another ML technique useful for segmentation is the decision tree. This method involves splitting the dataset based on certain variables in a way that optimizes a predefined objective. A key advantage of tree-based methods is their interpretability: it is easy to see which variables drive the splits and to assess whether those splits make economic sense. Variable importance measures, like Information Gain, help interpret the decision tree by showing how much each split reduces the entropy (uncertainty). Lower entropy means the data is more organized, allowing for clearer and more meaningful segments to be created.
Estimation
Once the segments are defined, the final step involves applying prediction models to each segment. While the segments resulting from ML models can be used in traditional estimation models such as a logistic regression or a survival model, ML-based estimation models can also be used. An example of such an ML estimation technique is XGBoost. The method combines multiple small decision trees, learning from previous errors, and continuously improving its predictions. It was observed that applying this estimation method in combination with ML-based segments outperformed traditional methods on the used dataset.
Interpretability
Though the techniques show added value, a significant drawback of using ML models for both segmentation and estimation is their tendency to be perceived as black-boxes. A lack of transparency can be problematic for financial institutions, where interpretability is crucial to ensure compliance with regulatory and internal requirements. The SHapley Additive exPlanations (SHAP) method provides an insightful way for explaining predictions made by ML models. The method provides an understanding of a prediction model by showing the average contribution of features across many predictions. SHAP values highlight which features are most important for the model and how they affect the model outcome. This makes it a powerful tool for explaining complex models, by enhancing interpretability and enabling practical use in regulated industries and decision-making processes.
Figure 3 presents an illustrative SHAP plot, showing how different features (variables) influence the ML model’s prepayment rate predictions on a per-observation basis. These features are given on the y-axis, in this case 8 features. Each dot represents a prepayment observation, with its position on the x-axis indicating the SHAP value. This value indicates the impact of that feature on the predicted prepayment rate. Positive values on the x-axis indicate that the feature increased the prediction, while negative values show a decreasing effect. For example, the feature on the bottom indicates that high feature values have a positive effect on the prepayment prediction. This type of plot helps identify the key drivers of prepayment estimates within the model as it can be seen that the bottom two features have the smallest impact on the model output. It also supports stakeholder communication of model results, offering an additional layer of evaluation beyond the conventional in-sample and out-of-sample performance metrics.
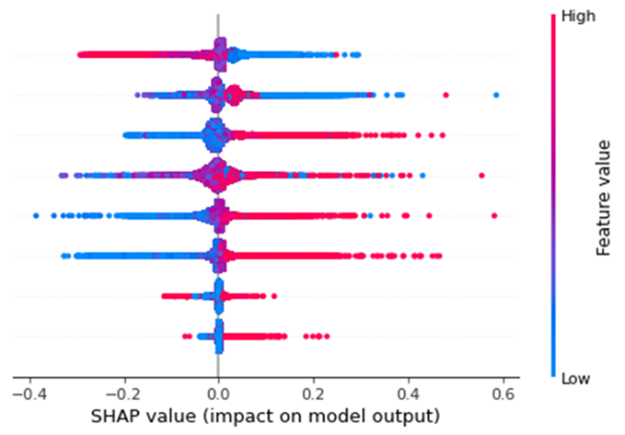
Figure 3: Illustrative SHAP plot
Conclusion
ML techniques can improve prepayment modeling throughout various stages of the model development process, specifically in data processing, segmentation and estimation. By enabling the full potential of ML in these facets, future cashflows can be estimated more precisely, resulting in a more accurate hedge. However, the trade-off between interpretability and accuracy remains an important consideration. Traditional methods offer high transparency and ease of implementation, which is particularly valuable in a heavily regulated financial sector whereas ML models can be considered a black-box. The introduction of explainability techniques such as SHAP help bridge this gap, providing financial institutions with insights into ML model decisions and ensuring compliance with internal and regulatory expectations for model transparency.
In the coming years, (Gen)AI and ML are expected to continue expanding their presence across the financial industry. This creates a growing need to explore opportunities for enhancing model performance, interpretability, and decision-making using these technologies. Beyond prepayment modeling, (Gen)AI and ML techniques are increasingly being applied in areas such as credit risk modeling, fraud detection, stress testing, and treasury analytics.
Zanders has extensive experience in applying advanced analytics across a wide range of financial domains, e.g.:
- Development of a standardized GenAI validation policy for foundational models (i.e., large, general-purpose AI models), ensuring responsible, explainable, and compliant use of GenAI technologies across the organization.
- Application of ML to distinguish between stable and non-stable portions of deposit balances, supporting improved behavioural assumptions for liquidity and interest rate risk management.
- Use of ML in credit risk to monitor the performance and stability of the production Probability of Default (PD) model, enabling early detection of model drift or degradation.
- Deployment of ML to enhance the efficiency and effectiveness of Financial Crime Prevention, including anomaly detection, transaction monitoring, and prioritization of investigative efforts.
Please contact Erik Vijlbrief or Siska van Hees for more information.





Citations
- See Surviving Prepayments: A Comparative Look at Prepayment Modeling Techniques - Zanders for a comparison between both types of models. ↩︎


