
Financial crime prevention (FCP) models play a critical role in protecting organizations from money laundering, fraud, and other illicit activities. The effectiveness depends on being able to adapt quickly as criminal tactics evolve.
Yet in many organizations, FCP models still follow the same rigid model validation (MV) process used for credit risk models, a process designed for stability, not agility.
While this ensures consistency, it leaves little room for the frequent updates these models desperately need. With regulators pushing for both effectiveness and compliance, and criminals moving faster than ever, the traditional approach is under pressure. Could generative AI, one of today’s most disruptive technologies, be the key to bridging the gap between strict validation requirements and the need for agility? Could it help us strike a better balance between speed, control, and cost?
The Current State of Model Validation in FCP
Currently, FCP model validation largely follows the framework used for credit risk models, but it faces several critical limitations:
- Manual, time-consuming and resource-intensive: Highly skilled validators must carefully review documentation, code, data pipelines, and monitoring outputs. Currently, it can take two people 6-8 weeks to complete a single validation, leaving them with little capacity to handle additional validations in parallel. In the time it takes to complete a validation, new criminal patterns may already be emerging which require updates or the development of a new model. In addition, delays in feedback between the validation team and developers could further extend the overall timeline.
- Costly: Compliance already consume significant budgets, and under cost-cutting pressures, it becomes increasingly difficult to justify allocating large teams to a single validation.
- Inflexible: Current validation approaches, built around credit risk frameworks, are primarily designed to safeguard capital adequacy. While effective for that purpose, they are not structured to keep up with the fast-moving and evolving patterns of financial crime.
- Capacity constraints: Given the size of most financial crime model portfolios and the frequency of validations required by internal policies, current resources are unlikely to meet long-term expectations. With model inventories expected to grow, this gap will only widen unless capacity is increased.
These challenges highlight a pressing reality: the current validation approach is no longer sustainable. Without significant improvements, organizations risk falling behind with both regulatory expectations and the fast-moving tactics of financial criminals.
Where Can GenAI Make the Biggest Impact in Validation?
In most organizations, models are assessed based on risk, complexity, and probability of failure. This tiered approach helps determine where automation, such as GenAI, can be applied most effectively.:
- High-risk, complex models – Models that are mathematically sophisticated, critical to operations or compliance, and have a higher probability of failure require thorough human validation and expert judgment due to their complexity and potential impact. Therefore, they are not well-suited for GenAI-based validation.
- Low-risk, simpler models – Models that are less mathematically complex, more standardized, and have a lower probability of failure. These are ideal candidates for GenAI, which can handle repetitive validation tasks, review documentation, and generate draft reports.
With GenAI taking care of routine checks on simpler models, human experts can dedicate their time and judgment to the models that truly require deep expertise.
The Role of AI in Financial Crime Model Validation
In practice, how can AI be applied to support model validation? At its core, AI is best suited to take on the repetitive and manual aspects of the process, the tasks that consume valuable time but add little judgment-based value. Instead of replacing experts, AI acts as an efficiency enabler – a “second pair of eyes” that enhances consistency, speeds up routine checks, and leaves human validators free to focus on areas where their expertise is irreplaceable.
Generative AI opens new possibilities for how validation might be approached, with AI driving the validation steps. Instead of starting from scratch, it could make it possible to ingest large volumes of model documentation and generate draft answers to validation questions which are informed by guidance documents, policies, and historical validation reports. It may also be possible to highlight areas that need further clarification, suggesting relevant follow-up questions for discussions between validators and model developers. Where responses are already sufficient, GenAI could enable the automatic closure of open points, keeping the process moving smoothly. Beyond Q&A, it creates the possibility of drafting validation findings based on prior patterns and even producing structured, section-by-section draft validation reports, giving validators a strong foundation to build on, rather than a blank page to start with. Final review and submission are always completed by the validator.
This shift highlights a clear evolution in validation practices. Currently, validation is often characterized by long checklists, manual document reviews, and labor-intensive report writing. With AI support, validation can become faster, more consistent, and highly scalable, allowing humans to focus on important aspects such as judgment, oversight, and final decision-making. With routine and repetitive tasks automated and accelerated through AI, and waiting times between interactions significantly reduced, validators could manage multiple validations in parallel. For model developers, this also means less time spent waiting on feedback, and therefore model developers can drive the speed of validation by submitting evidence faster. In short, AI doesn’t diminish the role of the validator – it elevates it, ensuring their expertise is applied where it delivers the most value. AI will transition the validator from an executor to a supervising role.
How would this Technically Work?
The goal is to create a simple, working version of the idea that shows how GenAI can support validators by automating repetitive steps while keeping humans in full control. It’s not about replacing expertise but about giving validators a smart assistant that can read complex documentation, provide the right information, and draft initial outputs they can refine.
At the center of this setup is an agentic framework built around two main parts: a Retrieval-Augmented Generation (RAG) system and a prompt creation engine. The RAG system helps the AI pull the most relevant content from internal guidance, policies, and historical validation reports. The prompt engine then turns that information into focused, context-aware prompts, so the AI can generate accurate, useful drafts. Everything runs securely in the organization’s existing cloud environment (for example, in Vertex AI on GCP) to make sure data stays protected and traceable.
The process could look like this:
- The model developer submits documentation, and the AI reviews it to identify relevant guidance and validation standards.
- It drafts initial responses to validation questions, giving the validator something concrete to start from instead of a blank page.
- If information is missing or unclear, the AI compiles structured follow-up questions that the validator can check and send back to the developer.
- When new evidence comes in, the AI reviews it, links it to the open items, and flags what can be closed or what still needs attention.
- Finally, it pulls everything together into a draft validation report with structured sections and proposed findings, ready for the validator to review and finalize.
In this target setup, the AI tool sits between the model developer and the validator. It manages the flow of documents and questions, keeps track of progress, and helps draft findings and reports. Validators remain in charge of every decision but can move through the process much faster and with more consistency. Developers, in turn, get clearer feedback and shorter waiting times.
The outcome is a smoother, more efficient collaboration where AI takes care of the manual groundwork, and humans focus on judgment and oversight, the parts that really matter.
Balancing Benefits and Risks
The potential of AI in model validation is not just theoretical; it comes with tangible benefits. First and foremost is efficiency: automation can significantly reduce the time spent on repetitive validation tasks, freeing experts to focus on higher-value activities. With a basic introduction of AI into the validation process, teams can achieve time savings of around 30%. When introducing a more advanced option, we believe an estimated time saving of up to 80% can be achieved. This naturally translates into cost savings, as the overall validation burden is lowered without compromising quality or increasing headcount. AI also promotes consistency and transparency, applying the same standards uniformly across models. Finally, it offers scalability as organizations can handle a larger portfolio of models without needing to increase headcount, a crucial advantage given current cost-cutting pressure.
As with any innovation, AI in model validation comes with significant risks that must be managed. Generative AI itself carries model risk, including bias, opacity, or “black box” behavior, which could undermine confidence if not carefully controlled. Additional concerns include autonomy risk, where AI might generate outputs without sufficient human guidance, leading to decisions that may be inappropriate or misaligned with validation standards; hallucination risk, where it produces information that seems plausible but is factually incorrect, which could mislead validators if not carefully checked; and incompleteness risk, where AI may overlook parts of a model or validation requirement, resulting in partial or insufficient coverage.
These risks can be managed by humans actively supervising AI and regularly reviewing its outputs. Mistakes are far less likely when experts double-check results, make sure nothing is missing, ensure all information provided is accurate, and stay in control of key decisions. Regulatory acceptance is also a consideration, as supervisors are likely to scrutinize the role of AI and require organizations to explain and justify its use. Finally, careful implementation prevents over-reliance on automation, ensuring human validators remain central to decisions where judgment is essential.
When implemented with care and proper oversight, AI can bring significant benefits to model validation. By combining AI’s capabilities with human judgment, organizations can work more efficiently, handle greater scale, and reduce costs, all while maintaining the trust and rigor that model validation requires.
Our FCP expertise:
Zanders brings a unique combination of expertise in both traditional and AI-driven model validation, helping to navigate the evolving landscape of financial crime model oversight. As a trusted advisor in risk, treasury and finance, Zanders combines deep regulatory knowledge with practical experience, ensuring that solutions are not only innovative but also fully compliant. More importantly, Zanders focuses on pragmatic, regulator-ready designs that bridge cutting-edge technology with compliance requirements. Zanders helps organizations work more efficiently while still meeting the high standards of rigor and trust that regulators expect.
Conclusion
In this FCP series, we have explored bias and fairness, explainability, and model and data drift. Each represents a vital aspect of building models that are not only powerful, but also responsible. Together, they remind us that the real challenge is not just creating models that work, but creating models that we can trust, understand, and sustain over time.
This is what makes AI-enabled model validation a natural next step. As models become more complex, risks evolve faster, and regulatory expectations increase. Organizations need human experts to focus on the areas where their judgment and oversight have the greatest impact, while AI handles the routine tasks.
As we conclude this series, the message is clear:
Organizations that embrace GenAI in their validation processes are not just improving efficiency, but they are shaping the future of model risk management.

AI for financial crime prevention
Get in touch to put GenAI into practice for your model validation process.
Contact us
The landscape these institutions are operating in is constantly changing. Criminals develop new behaviour, and new methods and technologies become available.
Criminals never stand still, and neither should the models designed to catch them. Across the financial sector, institutions have invested heavily in advanced Financial Crime Prevention (FCP) models to detect fraud and money laundering. Yet the environment these models operate in is evolving faster than ever. As new technologies emerge and criminal behaviors adapt, yesterday’s patterns no longer predict tomorrow’s risks.
Take cryptocurrencies: once niche, now mainstream. Their rise has transformed what “normal” transactions look like, blurring the line between legitimate activity and illicit movement. This shift underscores a growing challenge for banks—model drift. Without continuous monitoring and recalibration, even the most sophisticated FCP models can lose accuracy and allow financial crime to slip through the cracks.
Model Drift, Data Drift, Concept Drift – What Are They?
Model drift is defined as the degradation of the model’s performance over time. This can be due to many factors, such as sampling bias, but also due to data drift or concept drift. Data drift and concept drift are related and occur often at the same time, but tackle a different underlying issue.
Data drift occurs when the distribution of data underlying your model changes. Take for example, bank A which acquires bank B. Such a takeover might change the underlying customer base significantly. Assuming that bank B has a higher risk appetite, these clients likely require different monitoring from the original customer base, e.g. by changing thresholds or developing new rules.
Concept drift on the other hand means that a relationship that a model presupposes deteriorates or does not exist anymore. This can have large effects on the quality of model predictions. For example, criminals continuously develop new money laundering tactics to avoid being detected by ever-improving transaction monitoring models without impacting overall transaction distributions. This way the model still detects the outdated method the criminals used to apply but not the new methods. As a result, the model decreases in effectiveness.
As mentioned above, data drift and concept drift often occur together. An example of these two concepts coming together is for the aforementioned cryptocurrencies. The distribution of cryptocurrencies have shifted significantly with more and larger transactions indicating data drift. In addition cryptocurrencies have gained a lot of popularity amongst criminals for developing new money-laundering schemes indicating concept drift.
How To Monitor Model Drift
Both concept and data drift can occur after the go-live of the model. It is crucial to have proper monitoring in place to timely be alerted. Generally, model monitoring frameworks include periodic review of a models’ effectiveness. Creating awareness for data drift and concept drift during this periodic review can create an alertness if the model performance or underlying distribution significantly shifts. Besides the regular assessment cycle, some monitoring thresholds can be upheld:
- Data drift: measure the underlying distribution of risk drivers at model initiation. Significant distortions in this initial distribution should be bound to some pre-defined limit. Once these thresholds are breached, a review can be initiated to assess its contribution in erroneous predictions. An example of a metric that could be used for this purpose is the Population Stability Index (PSI), which measures the difference between the distributions of two different population samples.
- Concept drift: measure the predictive power of the individual risk drivers against the dependent variable. If there seems to be significant deterioration of the explanatory power, a review of the model design can be initiated. For example by using SHAP-values, the individual contribution of a risk driver towards the general risk classification can be utilized. If these SHAP-values provide a decrease in explanatory power since model initiation, this can indicate concept drift.
Prevent Drift From Derailing Your Models
Besides a solid model monitoring framework and regular periodic reviews of the model, model drift should also be considered during model development. During model (re)development, the following points should be considered to counteract model drift:
- Measure the sensitivity of the model against small changes in averages of your input. Assessment of the impact of changes in individual risk drivers can give insight into over-reliance towards specific characteristics that are prone to change.
- Sensitivity can also be measured towards the change in distribution, such as flattening or skewing the distribution.
- Assess the change to your model when risk drivers are removed. Here, again, the impact should be manageable.
- Investigate the stability of your risk drivers over time.
- Perform a qualitative analysis on the robustness of risk drivers.
These steps give a solid base to include mitigants for data drift and concept drift into your model development cycle.
This article is part of a larger series highlighting crucial topics for the future of financial crime prevention. See an overview of the whole series here.
Creating a solid model development framework that includes model and data drift can be a challenge and requires deep domain experience and experience. If you need guidance in making your models future-proof, Zanders can help.
Want to know how Zanders can support you in this transition? Feel free to reach out through our contact page to get in touch with an expert.

Get FCP support
Talk to an expert to prevent drift from derailing your models and make sure you're set up for the future.
Contact
In banks’ boardrooms and compliance departments, a quiet but persistent concern echoes: “Can we trust AI in high-stakes decision-making?”
For many companies, especially in regulated industries like finance, the fear of AI is not just philosophical; it’s a practical challenge. It stems from a perceived loss of control, a lack of transparency, and the worry that decisions made by complex models might be difficult to justify to regulators, auditors, or the public.
This fear is understandable. When machine learning models autonomously flag transactions, deny loans, or possibly even escalate alerts to authorities, the stakes are high. The consequences affect not just business outcomes, but reputations, regulatory standing, and real people’s lives. In Financial Crime Prevention (FCP), where analysts must decide whether to file a Suspicious Activity Report (SAR), the need for clarity is of great importance.
This fear doesn’t have to mean that these models have no place in these departments. Rather, it can guide us to the correct place. The focus should shift from: "how the model works" to: "how the model helps."
Empowering Analysts
In AI deployments, explainability is treated as a technical afterthought, a set of metrics or plots that satisfy internal documentation or regulatory checklists. But in FCP, the true end-user of an AI system is the analyst. They are the ones who must interpret alerts, justify decisions, and ensure compliance. Their job is not to understand gradient boosting or SHAP values, analysts should have a focus to make the results defensible and take informed decisions under pressure.
Human-centered explainability means designing explanations that support this task. It’s not about simplifying for the sake of clarity, it’s about making the explanation meaningful and relevant to the task at hand. This approach should turn the model from a black box into a collaborative partner.
Instead of presenting abstract SHAP plots, one could consider:
- Top contributing risk factors for each alert, along with an explanation of what each factor represents. While most models already use feature importance to describe their behavior, analysts tend to interpret these factors from a risk perspective. A simple way would be providing a mapping between model features and risk indicators which could help analysts better understand what drives an alert and why it matters.
- Narrative summaries that explain why a transaction deviates from expected behavior. One could for instance leverage the power of LLM’s for transforming data into plain-language interpretations.
- Consistency checks that show how similar cases were treated, building trust in the system’s fairness.
Too often, explainability efforts focus on stakeholders around the model; data scientists, compliance officers, or regulators. But the real test of explainability lies with the analyst who must act on the model’s output. By centering design on their needs, we shift the conversation from how the model works to how the model helps.
This shift doesn’t just improve usability; it builds trust. And in a domain like FCP, trust is everything.
Explainability as a Bridge, not a Barrier
AI continues to be a sensitive topic in the risk-conscious world of Financial Crime Prevention, largely because its explainability focuses heavily on technical model details. But the real value of AI lies in how it supports analysts, helping them interpret alerts, make informed decisions, and justify their actions with confidence. That’s why explainability should be designed with the analyst in mind. By doing this, AI becomes not only more transparent, but also more useful, more responsible, and more trusted.
Understanding and applying explainability metrics in Financial Crime Prevention (FCP) is no longer just a technical exercise, but a human-centered challenge.
As highlighted in our blog series on the future of FCP, explainability is just one of the critical pillars shaping responsible AI adoption in this domain. If you're navigating the complexities of explainability and wanting to ensure your AI systems are not only compliant but also trusted and usable by those on the front lines, Zanders can help.
Get AI support
Talk to an expert about ensuring AI compliance and usability in financial crime prevention.
Contact
In recent years, bias and fairness in AI models have become critical topics of discussion, especially as algorithmic decision-making has led to unintended and sometimes harmful consequences for specific groups.
In recent years, bias1 and fairness in AI models have become critical topics of discussion, especially as algorithmic decision-making has led to unintended and sometimes harmful consequences for specific groups. Notable examples include the “Toeslagenaffaire “ in The Netherlands (Toeslagenaffaire) and the COMPAS case in the United States (COMPAS case). Both of these examples highlight how models that include algorithmic decision making can display unwanted bias without proper governance.
In the Financial Crime Prevention (FCP) domain, AI models are often used to detect criminal behaviour such as fraudulent transactions, money laundering, and tax evasion. These models are not just operational tools – they are subject to regulation. For instance, National Central Banks may mandate that banks demonstrate sufficient effort in identifying financial crime (The DNB on Money Laundering and combating criminal money), with penalties for underperformance. Performance is typically measured using (a derivative of) recall2, which measures the model’s ability to identify as many true cases of criminal behaviour as possible.
Recently, several Dutch banks faced fines from regulators for failing to meet these requirements, underscoring the pressure to maximize recall.
However, this focus on maximizing recall must be balanced with fairness. Regulators also require banks to detect and mitigate unwanted bias in their models (EBA report, AI Act), which relates to the metric precision2 – the proportion of flagged cases that are actually criminal. A low precision rate can result in clients being wrongly flagged, which raises ethical and legal concerns.
The Pitfalls of Conventional Bias Fixes
Assessing the fairness of a model typically includes comparing precision-like metrics across different groups with similar sensitive information (e.g., groups based on gender or ethnicity). If significant disparities are observed between groups, steps are typically taken to align the precision values more closely. While this approach is popular and intuitive, it comes with several challenges:
- Conflicting objectives: Precision and recall are inherently at odds. Optimizing for one generally compromises the other. Banks must navigate regulatory demands for high recall while also ensuring fair treatment across groups, with no established best practices to guide these trade-offs.
- Levelling down: Achieving equal precision across groups can involve either improving the disadvantaged group's performance or reducing the advantaged group's performance. In practice, improving precision for disadvantaged groups is often infeasible due to limited data or inconsistent behavioural patterns. This leads to "levelling down" – artificially lowering the precision of the advantaged group to achieve parity (The Unfairness of Fair Machine Learning: Levelling down and strict egalitarianism by default). While this may equalize precision metrics, it does not improve outcomes for the disadvantaged group and often degrades overall model performance. Therefore, whether this approach is truly fair remains a subject of debate.
In the context of FCP, one could challenge the assumption that the goal should be to achieve strict statistical parity between groups at the cost of lower recall. For a model that e.g. detects fraudulent transactions, achieving strict parity by decreasing the recall for advantaged groups could be considered inappropriate, with potentially harmful societal consequences. Levelling down is a classic example of Goodhart’s Law that “when a measure becomes a target, it ceases to be a good measure”. - Use of sensitive information: Testing for unwanted model bias usually involves customer segmentation based on sensitive attributes. However, this process can lead to the sensitive data being used in the model development process, either directly (e.g., as input features) or indirectly (e.g., through group-specific decision rules or parameters). Under the General Data Protection Regulation (GDPR), this is generally prohibited.
Potential Next Steps
Bias and fairness considerations, especially within Financial Crime Prevention, require moving beyond the simple pursuit of strict statistical parity. In addition to established practices, more nuanced and responsible approaches should be considered:
- Establish a bank-wide “bias and fairness” committee: Create a bank-wide diverse committee consisting of experts across different departments such as modeling & data, compliance, and risk. This committee should define unified fairness principles, oversee their consistent application across departments, and act as a governance hub for addressing emerging fairness concerns in AI-driven decision-making.
- Develop an impact-based fairness framework: Move beyond solely equalizing metrics by building a framework that measures the tangible impact of bias on different customer groups. This enables institutions to focus resources where potential harm is greatest, ensuring fairness interventions deliver meaningful outcomes.
- Leverage explainability tools to detect hidden biases: Tools like SHapley Additive exPlanations (SHAP) are commonly used to meet regulatory requirements regarding explainability. Beyond compliance, SHAP can also help uncover which (combinations of) features act as proxies for sensitive attributes like gender or ethnicity. This could help to proactively detect hidden biases and strengthen fairness in FCP models.
This article is part of a larger series highlighting crucial topics for the future of financial crime prevention. See an overview of the whole series here.
Navigating the complex ecosystem of bias and fairness metrics in the context of FCP demands deep domain expertise and a clear understanding of the regulatory and ethical landscape. If you need guidance in translating complex fairness metrics into actionable, compliant, and effective practices, Zanders can help.
Citations
- Note that in this blog, bias refers to ethical bias. Specifically, cases where a model produces systematically more favorable or unfavorable outcomes for certain groups of individuals based on sensitive attributes such as ethnicity, gender, or similar characteristics. ↩︎
- In the bias and fairness literature, there is a large amount of metrics used, typically categorized in Independence, Sufficiency and Separation metrics (see e.g. A clarification of the nuances in the fairness metrics landscape | Scientific Reports ). For the purpose of this blog, the metrics Precision and Recall are used, as these are most commonly used within the context of FCP. ↩︎

On July 2nd, 2025, the European Banking Authority (EBA) published its consultation paper on the proposed Guidelines on the methodology institutions shall apply for their own estimation and application of Credit Conversion Factors (CCF) under the Capital Requirements Regulation (CRR).
As part of the consultation process, open until 29 October 2025, the credit risk specialists at Zanders share our perspective on the proposed guidelines levering on our extensive expertise in credit risk modeling.
Building on existing EBA guidelines on PD and LGD estimation, the new CCF guideline aims to strengthen consistency across all IRB risk parameters. The proposed guideline provides clearer direction and changes on topics such as:
- Level of modeling: facility-level realized CCFs are required, where aggregation possibilities are limited, and fully drawn facilities are explicitly included in scope.
- Realized CCF: a methodology is provided to determine the CCF based on the level of utilisation.
In addition, the guidelines simplify regulatory expectations compared to the Guidelines on PD and LGD estimation such as:
- Representativeness: model performance outweighs representativeness constraints.
- Risk quantification: the long-run average should be the facility-weighted average of realized CCFs.
- Downturn adjustments: only the extrapolation approach is permitted.
- In-default CCF estimation: the methodology for non-defaulted exposures also applies to defaulted exposures.
- Non-retail exposures: under certain conditions a simplified approach allows using the same CCFs for non-defaulted and defaulted exposures, where estimated drawings for unresolved defaults are omitted.
Recognizing the smaller scope of CCF and data availability compared to PD and LGD, the proposed guidelines introduce a more proportionate and pragmatic approach for CCF estimation.
This article highlights these developments, focusing on the level of modeling, the determination of realized CCF, and the simplified approaches to representativeness, risk quantification, and downturn estimation.
Level of Modeling and Application
Under Article 4(1)(56) of the CRR3, institutions are required to calculate the realized CCF at the level of each individual facility for every default. The EBA’s proposed guidelines enforce this requirement by mandating a separate realized CCF for each facility, allowing exceptions only when several revolving limits stem from related contracts linked through an overarching agreement (i.e. umbrella facility with a shared debt ceiling) and have comparable characteristics.
This represents a clear difference from the flexibility allowed under ECB’s Guide to Internal Models (EGIM) paragraphs 259 and 316, which do not require comparability of characteristics. Under EGIM it is allowed to aggregate at a higher level than the individual facility irrespective of product characteristics, such as aggregation when LGD is estimated at a higher level. The proposed EBA guidelines therefore tightens the existing framework by explicitly prohibiting the aggregation of contracts with very different characteristics.
For institutions, this means developing a deeper understanding of the customer’s product structure and closely monitoring changes in the product mix during the twelve months leading up to a default. A facility is in scope of the CCF model if it contains a revolving contract at the reference date. Contracts that become revolving or non-revolving after a restructuring within the same facility are therefore also included. However, repayments on term loans should not impact the CCF, meaning term loans at the reference date should effectively be excluded. Therefore, institutions must continue to track the exposure as part of the original commitment. This can lead to complex situations, as illustrated below. The brown-highlighted contracts (originating from term loans) are out of scope, while the green-highlighted contracts are in scope. The new contract III is considered in scope because it can be interpreted as an increase in the facility limit.
The realized CCF for this facility is calculated as the difference between the drawn amount at the default date (100 + 50) and the drawn amount at the reference date (50) divided by the undrawn amount at the reference date (50) of the contracts in scope. As a result, the realized CCF is ( (100+50)-50) / (100 – 50) = 200%.
Example:

Moreover, when several facilities are backed by the same collateral, they are often combined into a single recovery account during the recovery process (see example below). In such cases, these facilities can be grouped for LGD. Under the EGIM framework, there was flexibility to also aggregate them for CCF modeling. However, the new guidelines require institutions to precisely allocate outstanding amounts to each specific revolving facility that existed at the reference date. This can create inconsistencies between LGD and CCF modeling and adds complexity to the modeling process. As a result, institutions will need to improve their systems to consistently identify, link, allocate, and manage facilities across their portfolios.
Example:
An obligor has an overarching collateral securing two different facilities I and II. Both facilities consist of revolving off-balance sheet exposures, but have different characteristics. During the recovery process, they are combined into a single recovery account. Therefore, all these facilities are grouped for LGD.
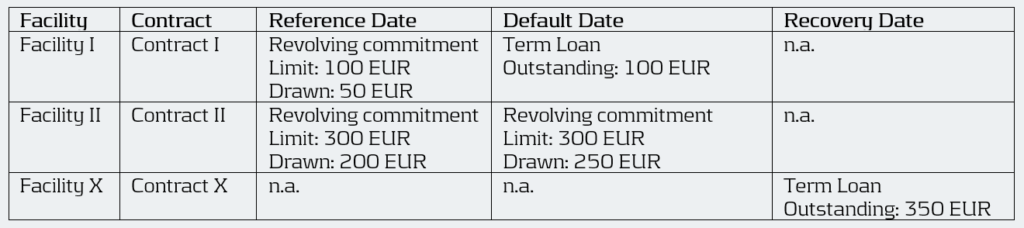
Under EGIM it was permitted to calculate the CCF at the LGD aggregation level, resulting in a realized CCF of ((100 + 250) – (50 + 200)) / ((100+300) – (50+200)) = 66.7%. Under the proposed guidelines, however, the realized CCF must be calculated separately for each facility, giving a CCF of 100% for Facility I (i.e. (100 – 50) / (100 – 50)) and 50% for Facility II (i.e. (250 – 200) / (300 – 200)).
Calculation of Realized CCF
The proposed EBA guidelines introduce two key changes in how institutions determine the realized CCF.
While EGIM paragraph 317 could be interpreted as fully drawn facilities are out of scope, the first change explicitly brings fully drawn revolving commitments into the scope of IRB-CCF modeling, marking another key difference between the two frameworks. EBA’s proposed guidelines now distinguishes between three levels of facility utilization for CCF estimation:
- Fully drawn facilities.
- Near-fully drawn facilities, which fall within the so-called Region of Instability (RoI). For example, a facility with a EUR 1000 limit and EUR 995 drawn at the reference date. If an additional EUR 30 is drawn between the reference date and default, the CCF would be: (1020-995)/(1000-995) = 500%.
- Partially drawn facilities.
The realized CCF is in general determined by the difference in drawn amount at default and the reference date as a percentage of the undrawn amount at the reference date. Since fully drawn facilities have no undrawn part at the reference date, institutions must use an alternative calculation method that expresses the drawn amount at default as a percentage of the committed limit at the reference date. Facilities that are in the RoI, have a very small undrawn amount, which can result in unstable and unreliable realized CCF estimates. Although Basel III describes three possible methods to handle such cases, the guidelines recommend applying the same approach used for fully drawn facilities when predictive accuracy or discriminatory power is limited. They highlight that consistency in applying the chosen approach is essential. Moreover, institutions are expected to define clear thresholds that identify these cases, where it is essential to balance the need to capture outliers without including an excessive number of cases.
The second change concerns the treatment of additional drawings. For retail exposures, institutions retain the flexibility to include additional drawings either in the LGD or in the CCF estimation. For non-retail exposures, additional drawings must still be incorporated into the CCF estimates. In situations where the additional drawings are considered in the CCF all observed drawings should be considered. However, if there are many drawings and repayments, realized CCFs can in practice be very high and LGDs very low (see example below).
Example
The facility has a drawn amount of EUR 100 and a limit of EUR 120, meaning there is an undrawn amount of EUR 20. If the additional drawings would simply be summed, this would lead to a total drawn amount of EUR 60 and a total recovery amount of EUR 160. As a result, ignoring discounting, this would mean the CCF is EUR 60 / EUR 20 = 300% and the LGD would be ((EUR 100 + EUR 60) – EUR 160) / (EUR 100 + EUR 60) = 0%.
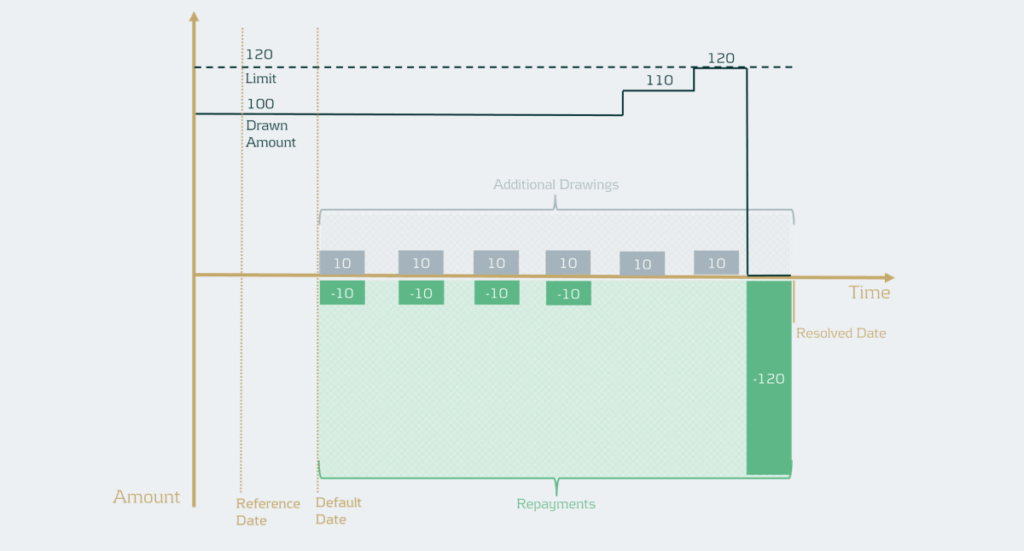
To address this, institutions should now calculate the realized CCF by increasing the drawn amount at default by the positive difference between the highest drawn amount after default and the drawn amount at default. Then the CCF would be (drawn amount at default + additional drawings during default – drawn amount at the reference date) / (limit at reference date – drawn amount at reference date). In the example, the facility has EUR 100 drawn and EUR 20 undrawn at default (and at the reference date for simplicity). The highest drawn amount during default is EUR 120, meaning EUR 20 of additional drawings instead of EUR 60 in the example. Ignoring discounting, this gives a CCF of ((100 + 20) – 100 ) / (120 – 100) =100%. This method uses outstanding balances rather than transaction-level data. It therefore differs from the transaction-based approach typically used in LGD modeling1. The drawn amounts used in the realized CCF and realized LGD should be consistent, meaning that if an institution currently applies a different method, the LGD model may need to be redeveloped.
Representativeness
While earlier guidelines placed heavy emphasis on ensuring representativeness in the development phase, the proposed guideline focusses on how well the model performs in terms of discriminatory power and homogeneity in rating grades or pools.
However, representativeness remains essential for the data used for developing, testing, and quantifying the CCF models, meaning institutions must still confirm that the data used reflects the characteristics of the application portfolio across different time periods, jurisdictions, and data sources. If the development or testing samples are not representative and this negatively affects model performance or its assessment, they must be redeveloped or adjusted. For the quantification sample, institutions should assess whether any lack of representativeness introduces bias in realized CCFs and apply appropriate adjustments or margins of conservatism where needed, without lowering CCF estimates. Compared to the previous Guidelines on PD and LGD estimation, the new guidelines therefore introduce a simpler approach focused on the performance of the model.
Risk Quantification
Under the EGIM framework, CCF quantification depends on whether the historical observation period is representative of the LRA. If it is, institutions should use the arithmetic average of yearly realized CCFs. If not, adjustments are made to account for underrepresentation or overrepresentation of bad years. The proposed guidelines, however, require a single arithmetic average of all realized CCFs weighted by the number of facilities. It is no longer allowed to use averages based on a subset of observations such as yearly averages. Therefore, potential recalibration is required.
Downturn
The downturn CCF guideline builds on the principles of downturn LGD estimation but introduces several simplifications. The haircut method is removed, as it is considered unsuitable for CCF estimation. Instead, institutions may apply an extrapolation approach at the overall CCF level to capture the direct link between economic factors and CCFs. When no observed or estimated downturn impact is available, a 15%-point add-on is maintained and the105% LGD-cap is removed. Additionally, institutions may apply downturn components estimated for non-defaulted facilities to defaulted ones, eliminating the need for separate downturn estimation and simplifying implementation.
The clarity provided by the new guideline on this topic supports the simplifications aimed to make the framework more pragmatic.
Conclusion
The EBA’s consultation on the new CCF modeling guidelines introduces notable simplifications compared to the previous framework, aiming to enhance consistency across all IRB parameters. While these changes support greater harmonization in credit risk modeling, they also may carry significant implications for institutions, particularly in the areas of level of modeling, realized CCF determination, and long-run average estimation. Adapting effectively to these developments will be essential for maintaining compliance and ensuring robust risk management practices.
The deadline for institutions to submit feedback to the EBA is next week October 29th 2025. Zanders therefore encourages institutions to evaluate the potential impact on their modeling practices and share insights based on their practical experience.
Reach out to John de Kroon, Dick de Heus, or Louise Schriemer if you are interested in getting a better understanding of what the proposed guidelines mean for your credit risk portfolio.
Citations
- Transactions can be derived from differences in outstanding balances and vice-versa. Therefore, this change is not blocking but usually requires some additional steps. ↩︎

The stakes are high: financial institutions collectively spend billions each year on combating financial crime.
In the Netherlands alone, more than €1.4 billion is spent annually on money laundering prevention, with an additional €1 billion in administrative burdens for companies and individuals1. These costs highlight not only the scale of the challenge, but also the urgent need for technological solutions, such as AI, that are both effective and efficient.
With the rapid rise of artificial intelligence (AI) and increasingly complex regulatory expectations, the field is changing at an unprecedented pace. Keeping up with new developments demands both the right technology and a solid grasp of its principles to maintain fairness, transparency, and effectiveness.
To explain the new developments and how to effectively integrated those, we’re launching a new blog series on the future of FCP: to explore how organizations can balance innovation with responsibility. We will explore the dive into the most pressing challenges in FCP modeling and show how AI and machine learning are shaping its development. Along the way, we’ll share insights on building trust and reliability in next-generation models, along with practical tips, discussion points, and industry perspectives for those working with these emerging technologies.
What to Expect
Each blog post in this series of 4 will focus on a specific topic that is crucial to the present and future of the FCP domain. The posts will follow the typical lifecycle of model development – starting with the development and concluding with validation:
- Bias and Fairness: AI models are powerful, but they don’t always treat everyone equally, as seen during the “Toeslagenaffaire” in the Netherlands or COMPAS case in the United States. In high-stakes domains like FCP such consequences can be just as severe. In the rush to make AI models “fair”, many organizations fall into the trap of chasing strict statistical parity at the expense of performance and context. In FCP, this tension is especially acute: regulators push for ever-higher recall, while fairness requirements demand balanced precision across different groups. The result? Conflicting objectives, artificial “levelling down,” and potential compliance risks under GDPR. The conventional bias-mitigation mindset is challenged, where a more mature, context-aware approach to fairness is advocated for.
- Explainability: AI and ML models go hand in hand with the challenge of explainability. These technologically advanced models are frequently described as black boxes: powerful, yet difficult to interpret In practice, model developers outsource the responsibility for model interpretability to SHAP or similar feature-importance methods – and call the job done. But does this really provide meaningful insight into how a model behaves? In FCP, explainability must go beyond technical metrics; it should focus on the people who use these models every day. The real value of AI in this space often lies in how it supports analysts – helping them interpret alerts, make informed decisions, and justify their actions. This article explores how shifting from model-centric to human-centric explainability can transform AI from a black box into a trusted, collaborative partner in the fight against financial crime.
- Model Drift and Data Drift: The financial world is always in movement. As technologies evolve and customer behaviour shifts, models built to detect financial crime can quickly become outdated. This article explores the importance of monitoring data drift (changes in input patterns) and modeldrift (changes in the relationships between inputs and outcomes). From building models that can withstand shifting behaviour to setting smart thresholds and review cycles, it highlights how banks can keep their FCP models relevant and reliable.
- The Model Validation Process: Model validation in FCP has long followed the same framework as credit risk – a framework often characterized by manual, time-consuming, and inflexible processes. With criminals constantly adapting their tactics and regulators becoming ever more demanding, this traditional approach is no longer sustainable. This article explores how generative AI can transform model validation without replacing human expertise. When implemented with care and oversight, AI elevates validators, ensuring their skills are applied where they matter most and keeping FCP programs agile in a rapidly evolving landscape.
By progressing through these topics in order – from identifying risks of bias, to ensuring transparency, to monitoring drift, and finally to examining validation frameworks – a clear narrative is created that links principles to practice. Responsible innovation is not just about ticking boxes on a regulatory checklist, it’s about creating an FCP framework that people can trust. These blogs offer insights and perspectives for making this happen.
Looking Ahead
This series of upcoming blog posts is just the beginning. Each topic opens the door to deeper discussions, case studies, and practical applications. Whether you’re a risk manager, data scientist, compliance officer, or executive, the series provides insights into the challenges and practical approaches that financial institutions can take to address them.
Citations
- Grootbanken voorzien verlies van duizenden banen bij witwascontroles - Financieel Dagblad, October 2nd ↩︎

Reducing false positives in AML detection by refining peer groups and anomaly scoring models.
We have developed a machine learning model for a leading Dutch bank with over EUR 300 billion in assets to detect potential money laundering activities within its high-net-worth client segment.
Challenge
Anti-Money Laundering (AML) models typically struggle with a common issue: a limited number of true positive cases for effective model training. To address this, most AML models incorporate some form of anomaly detection to identify unusual patterns in client behavior.
We focused on the bank’s wealthiest clients, identified by a minimum asset threshold. This presents a unique challenge because, by nature, these clients are already statistical outliers. As a result, we needed to identify anomalies within this group of outliers, significantly increasing the model's complexity.
The bank has an existing model in place, and our role is to enhance its performance, with a focus on:
- Redeveloping peer groups
- Reducing false positives in AML detection
Model Development
Like most machine learning projects, the development lifecycle is divided into three key phases: feature engineering (which takes up most of the time), modeling, and testing/implementation.

We designed model features to ensure that normal client behavior corresponds to lower values, while anomalous behavior triggers higher values. This approach enhances the effectiveness of anomaly detection models.
Collaborating closely with operations analysts, we refined these features to minimize obvious false positives among top-scoring cases. As a result, clients with legitimate activities are less likely to receive high anomaly scores in the final model.
Peer Groups
Detecting anomalous behavior among high-net-worth clients—who are all outliers by nature and exhibit highly diverse transaction patterns—requires a nuanced approach. To address this, we grouped clients based on their transaction behaviors to form peer groups.

Key features were then evaluated by measuring how much a client’s behavior deviated from that of their peers. This method identifies anomalies by comparing clients to peers with similar transaction patterns.
Our role involved revisiting and refining these peer groups to enhance the effectiveness of peer-based features, ultimately improving the model’s overall performance.

For more information, visit our Financial Crime Prevention page, or reach out to Johannes Lont, Senior Manager.

Discover how AI-powered fraud detection is transforming the fight against VAT fraud in banking, increasing precision and efficiency.
VAT Carousel Fraud (VCF) is a significant issue in the EU, costing an estimated €25-50 billion annually. We helped one of the largest Dutch banks become the first to develop a machine learning model specifically tailored to detect this type of fraud.
Challenge
A team within the bank manually identified several cases of VCF each month. The objective was to develop a machine learning model to replace these investigations while leveraging the team’s expertise. The challenge was to create an effective model despite having a limited number of true positive cases for training.
Model Development
Most Anti-Money Laundering (AML) models focus on detecting a broad range of money laundering activities. However, anomaly detection models are particularly effective at identifying outliers across diverse behaviors.
In the case of VAT Carousel Fraud (VCF), the behavioral patterns of the missing trader role are more distinct and consistent. To address this, we implemented a hybrid approach that combines supervised and unsupervised machine learning models.
The approach is summarized in the following steps:
1 - Feature Engineering
- Converted risk indicators into features, focusing on aspects like network structures and rapid movement of funds.
2 - Supervised Model
- Employed XGBoost to identify missing traders within the carousel fraud.
- Utilized all available true positives to train the model on recognizable patterns.
3 - Unsupervised Model
- Implemented Isolation Forest to detect other roles in the carousel fraud.
- Focused on outlier detection to identify anomalous behavior.
Performance
Given the large scale of VAT fraud within the EU and the well-defined transactional typologies, we expect the model to deliver strong performance.
The first VAT Carousel Fraud (VCF)-specific models are now in production. A set of alerts was generated using real transaction data and reviewed by experienced analysts, achieving a 20% precision rate in identifying suspicious activities.
VCF explained
VAT carousel fraud, also known as missing trader fraud, exploits the VAT system by allowing companies to import goods VAT-free within the EU, sell them domestically while collecting VAT, and then fail to remit the VAT to tax authorities.
The goods are sold through a chain of companies and eventually exported again, enabling the final exporter to reclaim the VAT. This cycle can be repeated multiple times, leading to substantial tax losses for governments.
For more information, visit our Financial Crime Prevention page, or reach out to Johannes Lont, Senior Manager.

Transforming financial crime data management from reactive compliance to strategic insight.
We have helped a Dutch bank with over 500 billion in assets understand and realize their data ambitions regarding customer due diligence, sanctions, transaction monitoring, and fraud.
Challenge
Entering the final stages of remediation, the bank wishes to develop a best-in-class data strategy in the financial crime domain. Having spent the last few years focusing on ensuring short-term compliance, the management team requested Zanders’ help to transition into an institution capable of tackling financial crime proactively.
This project aligns with a wider trend in the financial industry, where institutions, after addressing regulatory findings, invest in augmenting and automating their financial crime systems as a stepping stone toward an integration phase with a holistic view of client risk.

Solution
Zanders proposed a three-step approach:
- Step 1: Determine the current maturity state
- Step 2: Work along with stream leads to determine ambition
- Step 3: Create and execute a roadmap to guide the bank through until 2027
In Step 1, we determined the current state of data management regarding customer due diligence (CDD), sanctions, transaction monitoring (TM), and fraud. Since data is a multifaceted and all-encompassing element of an institution’s fight against financial crime, we divided our investigation into six key themes. This structure allowed for better alignment with stream leads within the bank while also enabling comparisons with best practices across the financial industry.
During Step 2, we assisted stream leads in identifying pain points and future objectives, thereby developing ambitions for each of the six themes. These ambitions balanced the bank’s desire to foster a cutting-edge data policy while still being actionable given the available resources—technical and otherwise.
Finally, in Step 3, not only did we bring all ambitions together into a coherent roadmap defining the data strategy through 2027, but we also began executing this roadmap immediately, minimizing the time between vision and realization to maximize value creation.

Moreover, a key deliverable was a comprehensive overview of the primary dataflows between departments. Our experience shows that, in trying to ensure short-term compliance, financial institutions often inherit a legacy of tangled dataflows, where data origins are obscured and key features are redundantly recalculated.
The first step toward resolving this issue was to carefully analyze how data flows between different pillars (Transaction Monitoring, KYC, Fraud Detection, and Sanctions). Once identified, inefficiencies and vulnerabilities were addressed through improved architecture and governance.
Making the Data Transformation Visual
The broad scope of this project, combined with the large amount of data it involves, poses a risk that stakeholders may struggle to stay informed about developments and decisions.
That’s why, from the very beginning, we committed to visualizing the ongoing transformations by creating a Data Initiative Dashboard to track progress on key data initiatives. This tool enables leadership to monitor and adjust priorities throughout the execution phase and establishes a gold standard for reporting future initiatives in an informative and intuitive manner.
For more information, visit our Financial Crime Prevention page, or reach out to Johannes Lont, Senior Manager.

Cutting costs and increasing accuracy with automated periodic reviews.
Our client faced a challenge with a large volume of KYC/CDD reviews that needed to be conducted periodically, but many did not contain material CDD risks. Zanders supported the development and management of the PR automation model, which automates cases requiring limited research and allows analysts to focus on more complex, high-risk cases.
Challenge
The traditional approach to CDD case handling requires significant manual effort by analysts. However, many cases that require minimal investigation are still reviewed manually. As a result, the current approach is neither risk-based nor cost-effective.
Typically, a Client Risk Rating model classifies clients as low, medium, or high risk. These clients are then reviewed at set intervals, such as every five, three, or one year(s), respectively. During these periodic reviews, analysts spend considerable time reviewing cases with no significant changes since the last manual review. This process is inefficient, and improvements can be made to make it more risk-based.
Solution
The PR automation model identifies cases that require minimal research and processes them automatically. The process begins with analyzing the current group of clients. From this large dataset, a subset of low-risk clients is identified based on expert knowledge combined with data analysis.
Next, the model determines which additional automated checks are necessary to ensure that the case has not undergone material changes since the last manual review. With these additional checks in place, the case can be processed automatically.
Automating PRs is only possible with a strong data foundation. Zanders assisted not only in developing the PR model but also in ensuring that data quality meets the necessary standards.

Performance
The PR automation model delivers significant cost savings while improving the efficiency and effectiveness of CDD case handling. Additionally, Zanders supports clients in demonstrating to regulators that this model helps transition to a more risk-based CDD approach.
For more information, visit our Financial Crime Prevention page, or reach out to Johannes Lont, Senior Manager.


